全文本搜索



1)CREATE TABLE语句接受FULLTEXT子句,它给出被索引列的一个逗号分隔的列表
2)在索引之后,使用两个函数Match()和Against()执行全文本搜索,其中Match()指定被搜索的列,Against()指定要使用的搜索表达式;传递给Match()的值必须与FULLTEXT()定义中的相同,如果指定多个列,则必须列出它们(而且次序正确)
SELECT note_text
FROM productnotes
WHERE Match(note_text) Against(‘rabbit’);

3)这条SELECT语句同样检索出两行,但次序不同(虽然并不总是出现这种情况)
SELECT note_text
FROM productnotes
WHERE note_text LIKE ‘%rabbit%’;
上述两条SELECT语句都不包含ORDER BY子句,后者以不特别有用的顺序返回数据。前者返回以文本匹配的良好程度排序的数据。两个行都包含词rabbit,但包含词rabbit作为第3个词的行的等级比作为第20个词的行高
4)演示排序如何工作
SELECT note_text,
Match(note_text) Against(‘rabbit’) AS rank
FROM productnotes


如果指定多个搜索项,则包含多数匹配词的那些行将具有比包含较少词(或仅有一个匹配)的那些行高的等级值
查询扩展用来设法放宽所返回的全文本搜索结果的范围
SELECT note_text
FROM productnotes
WHERE Match(note_text) Against(‘anvils’);
表中的行越多(这些行中的文本就越多,使用查询扩展返回的结果越好)
SELECT note_text
FROM productnotes
WHERE Match(note_text) Against(‘anvils’ WITH QUERY EXPANSION);
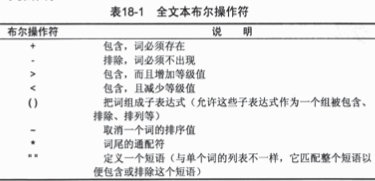
6)布尔文本搜索,以布尔方式,可以提供关于如下内容的细节:

SELECT note_text
FROM productnotes
WHERE Match(note_text) Against(‘heavy’ IN BOOLEAN MODE);
匹配包含heavy但不包含任意以rope开始的词的行:
SELECT note_text
FROM productnotes
WHERE Match(note_text) Against(‘heavy -rope*’ IN BOOLEAN MODE);